TOC
Web Scraping is important tool every Data Scientist should be familiar with. Often the data a client wants to analyze is not neatly packed in jsons or an enterprise data base, and you need to collect it yourself. When the data you need is on a webpage and there is no API available, web scraping will be the tool you need.
Today we will walk through a simple example where we need to collect a table from a web page. Our goal will be to collect all the hall of fame pitchers from Baseball Reference.
Web Scraping Basics
Web Scarping is the process of parsing HTML elements, which consist of tags that delineate the start and end of an element and optional attributes that describe the element.
Elements
Below are some of the most common elements.
<html>…</html>— The root element<head>…</head>— The document head<title>…</title>— The page title<body>…</body>— The page’s content<h1>…</h1>— A section heading.<p>…</p>— A paragraph.<a>…</a>— A link.<img>— An image.
Check out this site for more info.
Here is a basic page:
<html>
<head>
<title>My Website</title>
</head>
<body>
<h1>Heading 1</h1>
<p>This is a paragraph</p>
</body>
</html>Simple Example
To conduct our first web scraping task, we will use the read_html() function to convert our raw html into an html document object we can parse. Next, we will use the html_node() function to select the h1 element. Finally, we will use html_text() to extract the content in between the h1 tags.
library(rvest)
library(dplyr)
library(readr)raw_html <- '<html>
<head>
<title>My Website</title>
</head>
<body>
<h1>Heading 1</h1>
<p>This is a paragraph</p>
</body>
</html>'
html <- read_html(raw_html)
html## {html_document}
## <html>
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
## [2] <body>\n <h1>Heading 1</h1>\n <p>This is a paragraph</p>\n</body>html %>%
html_nodes("h1") %>% # grab the h1 elements
html_text() # extract the content## [1] "Heading 1"CSS Selectors
While selecting by elements is pretty straight forward, elements are often repeated multiple times on a single page. To make our request more specific, we can use CSS selectors.
CSS is used to style of the content of html documents, and CSS selectors are used to match CSS rules to elements in the html. We can use CSS selectors to traverse complicated HTML structure and extract the exact data we need. Below are the most common selectors I have used.
ElementSelectorClassSelectorIDSelector
Let’s walk through a simple example.
raw_html <- "<html>
<head>
<title>My Website</title>
</head>
<body>
<h1 id = 'header1'>Heading 1</h1>
<p>This is a paragraph</p>
<h1 class = 'header'>Heading 2</h1>
<p>This is a paragraph</p>
<h1 class = 'header'>Heading 3</h1>
<p>This is a paragraph</p>
</body>
</html>"
html <- read_html(raw_html)
html## {html_document}
## <html>
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
## [2] <body>\n <h1 id="header1">Heading 1</h1>\n <p>This is a paragra ...Below is how we can select by element, class, or id.
ElementSelector: useh1to select all<h1>elementsClassSelector: use.headerto select all elements withclassheaderIDSelector: use#header1to select the element withidattributeheader1
Now, let’s write the code to complete each of these tasks.
To get all the heading content, we use the h1 selector.
html %>%
html_nodes("h1") %>%
html_text()## [1] "Heading 1" "Heading 2" "Heading 3"To get the second and third headings, we can use the .header selector since both elements belong to the header class.
html %>%
html_nodes(".header") %>%
html_text()## [1] "Heading 2" "Heading 3"Finally, we can use the#header selector to get the content from the first heading. Note, id is unique for a particular element and cannot be repeated. Because of this fact, if an element has an id, it is often the easiest selector to use.
html %>%
html_nodes("#header1") %>%
html_text()## [1] "Heading 1"If you want more practice with CSS selectors, check out this page.
Real World Example
Now that we have reviewed the basics. Let’s try a real world example: scraping the hall-of-fame pitchers from https://www.baseball-reference.com/awards/hof_pitching.shtml.
Finding the CSS Selector
Luckily, most browsers offer support to find the selector you need without having to parse the entire html document. To get started, right-click on a page and select the inspect option. Next, as you can see in the screenshot below, click the the select tool and hover over the the part of the webpage that has your data. Once your data is in the blue box, left-click and the html element will appear on the right side. It will also show the CSS selector for that particular element in the box above your selection.
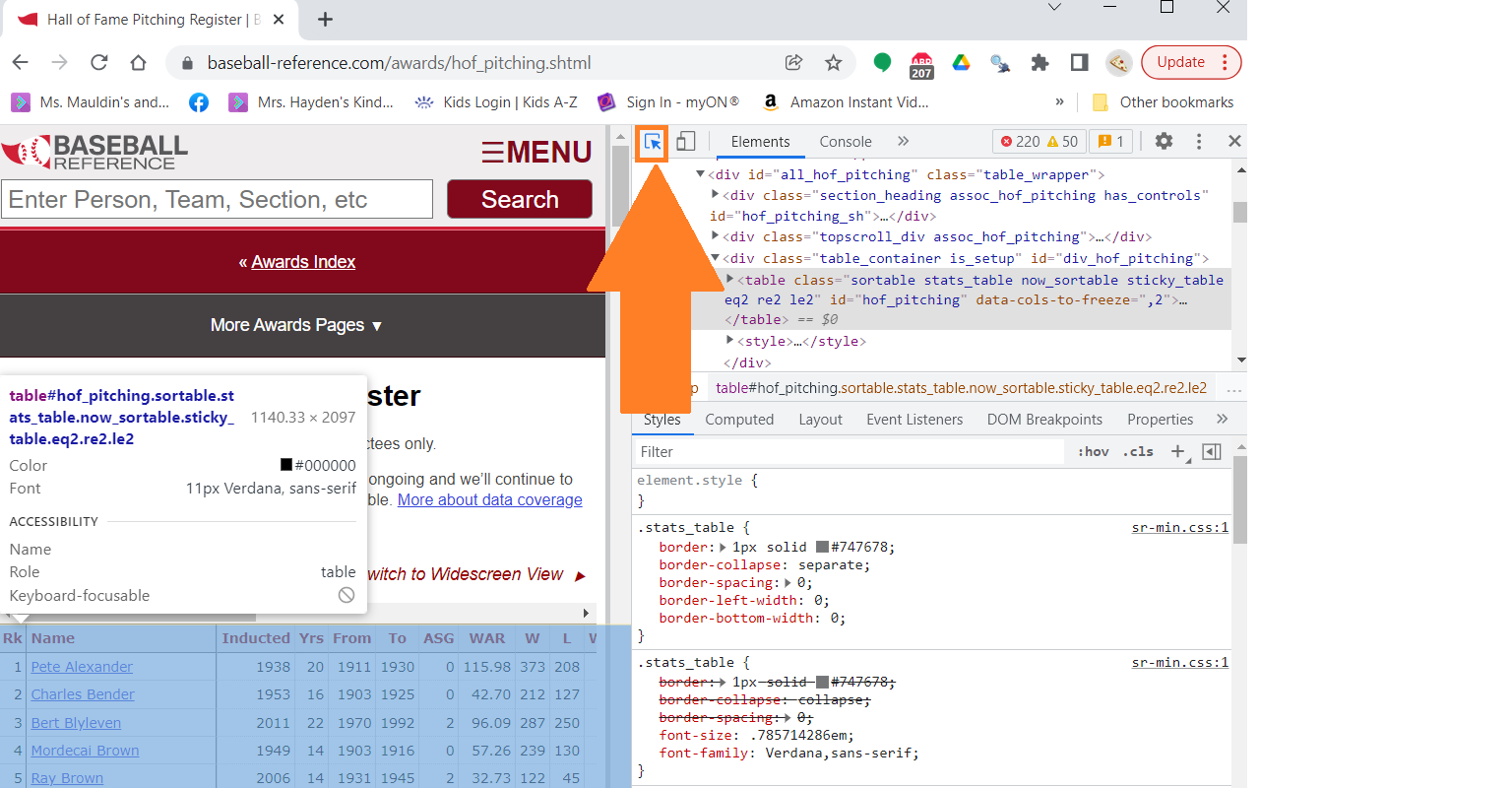
CSS Selector
You can even right click on the element in the window in the top right corner and copy the selector.
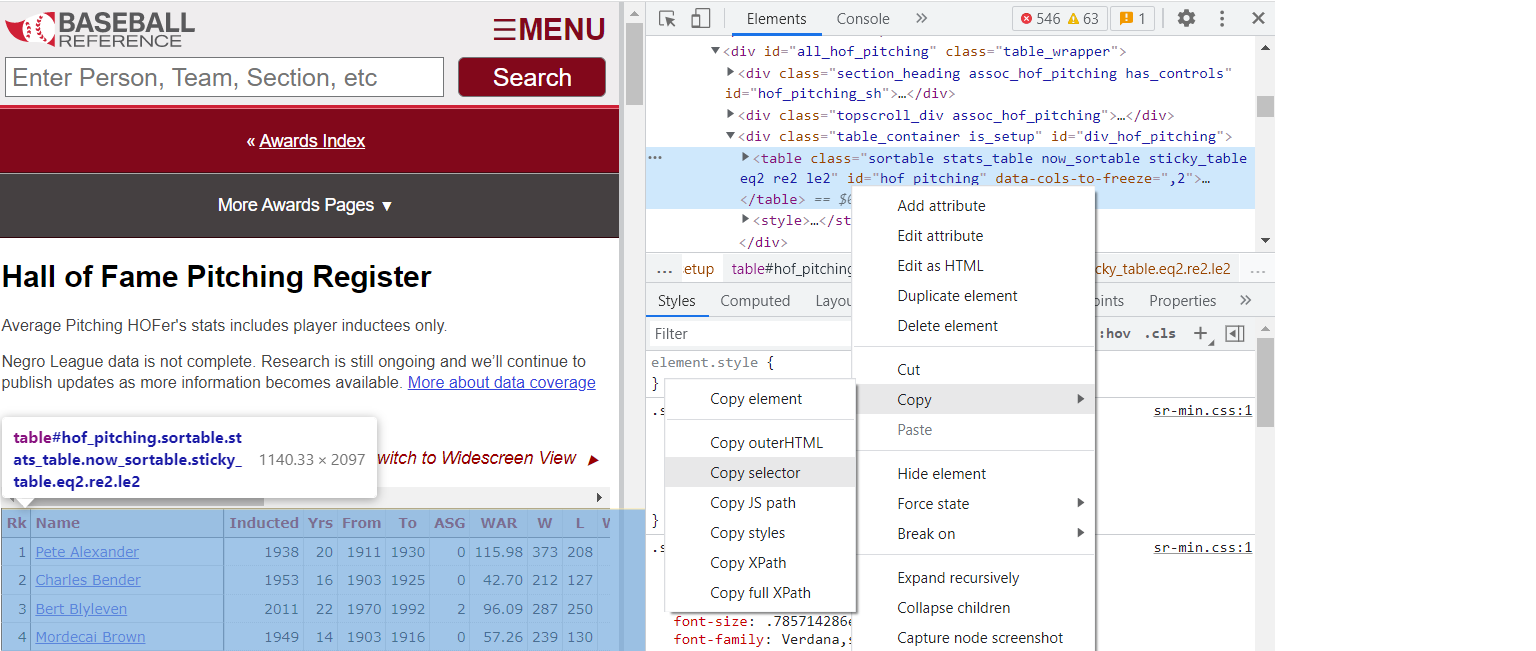
Copy CSS Selector
Extract the Data
Now that we have the selector, we can grab the data we need. Let’s start by reading the html.
url <- "https://www.baseball-reference.com/awards/hof_pitching.shtml"
html <- read_html(url)
html## {html_document}
## <html data-version="klecko-" data-root="/home/br/build" itemscope="" itemtype="https://schema.org/WebSite" lang="en" class="no-js">
## [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
## [2] <body class="br">\n<div id="wrap">\n \n <div id="header" role="banner"> ...Now we can grab the table using the #hof_pitching selector and will convert the table to a data frame using the html_table() function.
df_raw_pitchers <- html %>%
html_node("#hof_pitching") %>%
html_table()
glimpse(df_raw_pitchers )## Observations: 88
## Variables: 30
## $ Rk <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 1…
## $ Name <chr> "Pete Alexander", "Charles Bender", "Bert Blyleven", "Mordec…
## $ Inducted <int> 1938, 1953, 2011, 1949, 2006, 1996, 1994, 1946, 1963, 2006, …
## $ Yrs <int> 20, 16, 22, 14, 14, 17, 24, 11, 12, 14, 14, 6, 10, 12, 14, 2…
## $ From <int> 1911, 1903, 1970, 1903, 1931, 1955, 1965, 1899, 1882, 1920, …
## $ To <int> 1930, 1925, 1992, 1916, 1945, 1971, 1988, 1909, 1894, 1939, …
## $ ASG <int> 0, 0, 2, 0, 2, 9, 10, 0, 0, 2, 0, 0, 9, 4, 9, 6, 0, 8, 7, 10…
## $ WAR <dbl> 115.98, 42.70, 96.09, 57.26, 32.73, 60.33, 84.13, 42.47, 84.…
## $ W <int> 373, 212, 287, 239, 122, 224, 329, 198, 328, 118, 215, 145, …
## $ L <int> 208, 127, 250, 130, 45, 184, 244, 132, 178, 64, 142, 94, 21,…
## $ `W-L%` <dbl> 0.642, 0.625, 0.534, 0.648, 0.731, 0.549, 0.574, 0.600, 0.64…
## $ ERA <dbl> 2.56, 2.46, 3.31, 2.06, 3.02, 3.27, 3.22, 2.68, 2.81, 3.58, …
## $ G <int> 696, 459, 692, 481, 215, 591, 741, 392, 531, 288, 450, 242, …
## $ GS <int> 600, 334, 685, 332, 156, 519, 709, 332, 518, 183, 385, 241, …
## $ GF <int> 81, 112, 3, 138, 22, 39, 13, 52, 12, 44, 52, 2, 2, 77, 34, 5…
## $ CG <int> 436, 255, 242, 271, 139, 151, 254, 260, 485, 105, 223, 233, …
## $ SHO <int> 90, 40, 60, 55, 18, 40, 55, 35, 37, 12, 38, 19, 8, 26, 49, 2…
## $ SV <int> 32, 34, 0, 49, 13, 16, 2, 5, 5, 24, 21, 0, 3, 31, 6, 390, 27…
## $ IP <dbl> 5190.0, 3017.0, 4970.0, 3172.1, 1477.0, 3760.1, 5217.2, 2896…
## $ H <int> 4868, 2645, 4632, 2708, 1388, 3433, 4672, 2647, 4295, 1585, …
## $ R <int> 1852, 1108, 2029, 1044, 641, 1527, 2130, 1206, 2384, 811, 12…
## $ ER <int> 1476, 823, 1830, 725, 495, 1366, 1864, 864, 1417, 638, 990, …
## $ HR <int> 165, 40, 430, 43, 26, 372, 414, 39, 159, 52, 66, 12, 15, 95,…
## $ BB <int> 951, 712, 1322, 673, 392, 1000, 1833, 690, 1191, 357, 802, 1…
## $ IBB <int> 8, NA, 71, NA, 0, 98, 150, NA, NA, 1, 0, NA, 0, 47, 123, 91,…
## $ SO <int> 2198, 1711, 3701, 1375, 690, 2855, 4136, 1265, 1978, 719, 98…
## $ HBP <int> 70, 102, 155, 61, 28, 160, 53, 113, 80, 42, 30, NA, 14, 27, …
## $ BK <int> 1, 10, 19, 4, 0, 8, 90, 2, 0, 2, 1, 0, 0, 5, 10, 16, 2, 13, …
## $ WP <int> 38, 79, 114, 61, 4, 47, 183, 62, 182, 11, 35, 67, 1, 12, 82,…
## $ BF <int> 20893, 11901, 20491, 12450, 3601, 15618, 21683, 11632, 19146…There you have it, the data we wanted in a data frame.
Data Cleaning
While the process above seemed very simple, web scraping is usually not this easy.
One task you will often have to complete with web scrapping is cleaning your data after extraction. In this example, the last row has the value “Average Pitching HOFer”, which would throw off our analysis if we did not know it was there. Always be sure to inspect the returned results for anomalies.
df_final <- df_raw_pitchers %>%
filter(!stringr::str_detect(Name, "Average"))
glimpse(df_final)## Observations: 87
## Variables: 30
## $ Rk <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 1…
## $ Name <chr> "Pete Alexander", "Charles Bender", "Bert Blyleven", "Mordec…
## $ Inducted <int> 1938, 1953, 2011, 1949, 2006, 1996, 1994, 1946, 1963, 2006, …
## $ Yrs <int> 20, 16, 22, 14, 14, 17, 24, 11, 12, 14, 14, 6, 10, 12, 14, 2…
## $ From <int> 1911, 1903, 1970, 1903, 1931, 1955, 1965, 1899, 1882, 1920, …
## $ To <int> 1930, 1925, 1992, 1916, 1945, 1971, 1988, 1909, 1894, 1939, …
## $ ASG <int> 0, 0, 2, 0, 2, 9, 10, 0, 0, 2, 0, 0, 9, 4, 9, 6, 0, 8, 7, 10…
## $ WAR <dbl> 115.98, 42.70, 96.09, 57.26, 32.73, 60.33, 84.13, 42.47, 84.…
## $ W <int> 373, 212, 287, 239, 122, 224, 329, 198, 328, 118, 215, 145, …
## $ L <int> 208, 127, 250, 130, 45, 184, 244, 132, 178, 64, 142, 94, 21,…
## $ `W-L%` <dbl> 0.642, 0.625, 0.534, 0.648, 0.731, 0.549, 0.574, 0.600, 0.64…
## $ ERA <dbl> 2.56, 2.46, 3.31, 2.06, 3.02, 3.27, 3.22, 2.68, 2.81, 3.58, …
## $ G <int> 696, 459, 692, 481, 215, 591, 741, 392, 531, 288, 450, 242, …
## $ GS <int> 600, 334, 685, 332, 156, 519, 709, 332, 518, 183, 385, 241, …
## $ GF <int> 81, 112, 3, 138, 22, 39, 13, 52, 12, 44, 52, 2, 2, 77, 34, 5…
## $ CG <int> 436, 255, 242, 271, 139, 151, 254, 260, 485, 105, 223, 233, …
## $ SHO <int> 90, 40, 60, 55, 18, 40, 55, 35, 37, 12, 38, 19, 8, 26, 49, 2…
## $ SV <int> 32, 34, 0, 49, 13, 16, 2, 5, 5, 24, 21, 0, 3, 31, 6, 390, 27…
## $ IP <dbl> 5190.0, 3017.0, 4970.0, 3172.1, 1477.0, 3760.1, 5217.2, 2896…
## $ H <int> 4868, 2645, 4632, 2708, 1388, 3433, 4672, 2647, 4295, 1585, …
## $ R <int> 1852, 1108, 2029, 1044, 641, 1527, 2130, 1206, 2384, 811, 12…
## $ ER <int> 1476, 823, 1830, 725, 495, 1366, 1864, 864, 1417, 638, 990, …
## $ HR <int> 165, 40, 430, 43, 26, 372, 414, 39, 159, 52, 66, 12, 15, 95,…
## $ BB <int> 951, 712, 1322, 673, 392, 1000, 1833, 690, 1191, 357, 802, 1…
## $ IBB <int> 8, NA, 71, NA, 0, 98, 150, NA, NA, 1, 0, NA, 0, 47, 123, 91,…
## $ SO <int> 2198, 1711, 3701, 1375, 690, 2855, 4136, 1265, 1978, 719, 98…
## $ HBP <int> 70, 102, 155, 61, 28, 160, 53, 113, 80, 42, 30, NA, 14, 27, …
## $ BK <int> 1, 10, 19, 4, 0, 8, 90, 2, 0, 2, 1, 0, 0, 5, 10, 16, 2, 13, …
## $ WP <int> 38, 79, 114, 61, 4, 47, 183, 62, 182, 11, 35, 67, 1, 12, 82,…
## $ BF <int> 20893, 11901, 20491, 12450, 3601, 15618, 21683, 11632, 19146…Extracting Additional Info
We may also want more than just the text content of the table. For example, the player names on the website are links to that players page. We may want those links so we can scrape those pages for additional data.
If we inspect the players name, we find the html element below:
<a href="/players/a/alexape01.shtml">Pete Alexander</a>An a tag is used for links and will have a href attribute for the link.
Instead of grabbing the text, we now want to grab the href attribute from the a element.
To get all the player links, we first grab the a elements from he table. Next, we use the html_attr() function to get the href attribute. Finally, to use this link, we need to add the baseball reference URL to the front of the link.
player_links <- html %>%
html_node("#hof_pitching") %>%
html_nodes("a") %>%
html_attr("href") %>%
stringr::str_c("https://www.baseball-reference.com", .)
player_links[1]## [1] "https://www.baseball-reference.com/players/a/alexape01.shtml"Now that we have the link to every players page, we can use the same process from above to get the year-by-year pitching data from each payers page, assuming that all the pages have the same structure.
Below is an example of collecting the year-by-year pitching data for the first HOFer on our list.
player_df <- player_links[1] %>%
read_html() %>%
html_node('#pitching_standard') %>%
html_table()
glimpse(player_df)## Observations: 28
## Variables: 35
## $ Year <chr> "1911", "1912", "1913", "1914", "1915", "1916", "1917", "1918"…
## $ Age <chr> "24", "25", "26", "27", "28", "29", "30", "31", "32", "33", "3…
## $ Tm <chr> "PHI", "PHI", "PHI", "PHI", "PHI", "PHI", "PHI", "CHC", "CHC",…
## $ Lg <chr> "NL", "NL", "NL", "NL", "NL", "NL", "NL", "NL", "NL", "NL", "N…
## $ W <chr> "28", "19", "22", "27", "31", "33", "30", "2", "16", "27", "15…
## $ L <chr> "13", "17", "8", "15", "10", "12", "13", "1", "11", "14", "13"…
## $ `W-L%` <chr> ".683", ".528", ".733", ".643", ".756", ".733", ".698", ".667"…
## $ ERA <chr> "2.57", "2.81", "2.79", "2.38", "1.22", "1.55", "1.83", "1.73"…
## $ G <chr> "48", "46", "47", "46", "49", "48", "45", "3", "30", "46", "31…
## $ GS <chr> "37", "34", "36", "39", "42", "45", "44", "3", "27", "40", "30…
## $ GF <chr> "11", "10", "9", "7", "7", "3", "0", "0", "3", "6", "1", "2", …
## $ CG <chr> "31", "25", "23", "32", "36", "38", "34", "3", "20", "33", "20…
## $ SHO <chr> "7", "3", "9", "6", "12", "16", "8", "0", "9", "7", "3", "1", …
## $ SV <chr> "3", "3", "2", "1", "3", "3", "0", "0", "1", "5", "1", "1", "2…
## $ IP <chr> "367.0", "310.1", "306.1", "355.0", "376.1", "389.0", "388.0",…
## $ H <chr> "285", "289", "288", "327", "253", "323", "336", "19", "180", …
## $ R <chr> "133", "133", "106", "133", "86", "90", "107", "7", "51", "96"…
## $ ER <chr> "105", "97", "95", "94", "51", "67", "79", "5", "45", "77", "9…
## $ HR <chr> "5", "11", "9", "8", "3", "6", "4", "0", "3", "8", "10", "8", …
## $ BB <chr> "129", "105", "75", "76", "64", "50", "56", "3", "38", "69", "…
## $ IBB <chr> "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ""…
## $ SO <chr> "227", "195", "159", "214", "241", "167", "200", "15", "121", …
## $ HBP <chr> "8", "6", "3", "11", "10", "10", "6", "1", "0", "1", "1", "3",…
## $ BK <chr> "1", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0…
## $ WP <chr> "4", "5", "3", "1", "2", "3", "1", "0", "1", "3", "1", "4", "2…
## $ BF <chr> "1440", "1290", "1234", "1459", "1435", "1500", "1529", "98", …
## $ `ERA+` <chr> "132", "128", "118", "122", "225", "172", "154", "163", "166",…
## $ FIP <chr> "2.83", "3.13", "2.66", "2.26", "1.82", "2.12", "1.84", "1.54"…
## $ WHIP <chr> "1.128", "1.270", "1.185", "1.135", "0.842", "0.959", "1.010",…
## $ H9 <chr> "7.0", "8.4", "8.5", "8.3", "6.1", "7.5", "7.8", "6.6", "6.9",…
## $ HR9 <chr> "0.1", "0.3", "0.3", "0.2", "0.1", "0.1", "0.1", "0.0", "0.1",…
## $ BB9 <chr> "3.2", "3.0", "2.2", "1.9", "1.5", "1.2", "1.3", "1.0", "1.5",…
## $ SO9 <chr> "5.6", "5.7", "4.7", "5.4", "5.8", "3.9", "4.6", "5.2", "4.6",…
## $ `SO/W` <chr> "1.76", "1.86", "2.12", "2.82", "3.77", "3.34", "3.57", "5.00"…
## $ Awards <chr> "MVP-3", "MVP-22", "", "MVP-10", "", "", "", "", "", "", "", "…Since we will want this data for all players, we need to reuse this code. Anytime you plan to reuse code, you should create a function. This will save copy and paste errors and allow you to modify it in the future without having to find every place in your code that you copy and pasted your initial process.
Let’s make a function that takes a players URL as input and outputs their year-by-year stats as a data frame.
get_player_stats <- function(url){
data <- url %>%
read_html() %>%
html_node('#pitching_standard')
#handles if the page does not have this table
if(length(data) == 0){
return(tibble::tibble())
}
data %>%
html_table(fill = TRUE)
}
player_data <- purrr::map(player_links, get_player_stats)
glimpse(player_data[[1]])## Observations: 28
## Variables: 35
## $ Year <chr> "1911", "1912", "1913", "1914", "1915", "1916", "1917", "1918"…
## $ Age <chr> "24", "25", "26", "27", "28", "29", "30", "31", "32", "33", "3…
## $ Tm <chr> "PHI", "PHI", "PHI", "PHI", "PHI", "PHI", "PHI", "CHC", "CHC",…
## $ Lg <chr> "NL", "NL", "NL", "NL", "NL", "NL", "NL", "NL", "NL", "NL", "N…
## $ W <chr> "28", "19", "22", "27", "31", "33", "30", "2", "16", "27", "15…
## $ L <chr> "13", "17", "8", "15", "10", "12", "13", "1", "11", "14", "13"…
## $ `W-L%` <chr> ".683", ".528", ".733", ".643", ".756", ".733", ".698", ".667"…
## $ ERA <chr> "2.57", "2.81", "2.79", "2.38", "1.22", "1.55", "1.83", "1.73"…
## $ G <chr> "48", "46", "47", "46", "49", "48", "45", "3", "30", "46", "31…
## $ GS <chr> "37", "34", "36", "39", "42", "45", "44", "3", "27", "40", "30…
## $ GF <chr> "11", "10", "9", "7", "7", "3", "0", "0", "3", "6", "1", "2", …
## $ CG <chr> "31", "25", "23", "32", "36", "38", "34", "3", "20", "33", "20…
## $ SHO <chr> "7", "3", "9", "6", "12", "16", "8", "0", "9", "7", "3", "1", …
## $ SV <chr> "3", "3", "2", "1", "3", "3", "0", "0", "1", "5", "1", "1", "2…
## $ IP <chr> "367.0", "310.1", "306.1", "355.0", "376.1", "389.0", "388.0",…
## $ H <chr> "285", "289", "288", "327", "253", "323", "336", "19", "180", …
## $ R <chr> "133", "133", "106", "133", "86", "90", "107", "7", "51", "96"…
## $ ER <chr> "105", "97", "95", "94", "51", "67", "79", "5", "45", "77", "9…
## $ HR <chr> "5", "11", "9", "8", "3", "6", "4", "0", "3", "8", "10", "8", …
## $ BB <chr> "129", "105", "75", "76", "64", "50", "56", "3", "38", "69", "…
## $ IBB <chr> "", "", "", "", "", "", "", "", "", "", "", "", "", "", "", ""…
## $ SO <chr> "227", "195", "159", "214", "241", "167", "200", "15", "121", …
## $ HBP <chr> "8", "6", "3", "11", "10", "10", "6", "1", "0", "1", "1", "3",…
## $ BK <chr> "1", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0…
## $ WP <chr> "4", "5", "3", "1", "2", "3", "1", "0", "1", "3", "1", "4", "2…
## $ BF <chr> "1440", "1290", "1234", "1459", "1435", "1500", "1529", "98", …
## $ `ERA+` <chr> "132", "128", "118", "122", "225", "172", "154", "163", "166",…
## $ FIP <chr> "2.83", "3.13", "2.66", "2.26", "1.82", "2.12", "1.84", "1.54"…
## $ WHIP <chr> "1.128", "1.270", "1.185", "1.135", "0.842", "0.959", "1.010",…
## $ H9 <chr> "7.0", "8.4", "8.5", "8.3", "6.1", "7.5", "7.8", "6.6", "6.9",…
## $ HR9 <chr> "0.1", "0.3", "0.3", "0.2", "0.1", "0.1", "0.1", "0.0", "0.1",…
## $ BB9 <chr> "3.2", "3.0", "2.2", "1.9", "1.5", "1.2", "1.3", "1.0", "1.5",…
## $ SO9 <chr> "5.6", "5.7", "4.7", "5.4", "5.8", "3.9", "4.6", "5.2", "4.6",…
## $ `SO/W` <chr> "1.76", "1.86", "2.12", "2.82", "3.77", "3.34", "3.57", "5.00"…
## $ Awards <chr> "MVP-3", "MVP-22", "", "MVP-10", "", "", "", "", "", "", "", "…One note with web scraping: error handling is a must when collecting data from numerous pages. You often run into unexpected formatting or a slight change in the page structure that will break your process. If you are scraping 100s of pages, you would hate to complete 95% of your collection only to have an unhandled error cause the process to stop, all collected data to be lost, fix the error, and rerun the whole process again.
For example, if you inspect the returned results from the player pages above, you will notice two players did not return results.
rows <- purrr::map_dbl(player_data, function(x) dim(x)[1])
player_links[rows == 0]## [1] "https://www.baseball-reference.com/players/r/ruthba01.shtml"
## [2] "https://www.baseball-reference.com/players/w/wardjo01.shtml"Both of these players were not primarily pitchers and have a different structure to their page. If we had not added if statement that checks if the webpage has our selector, the collection process would have broke and all data would have to be recollected.
This is part of the pain with web scraping and an important fact to keep in mind when estimating the feasibility of a task and the time it will take to complete it. What appears to be a simple task can turn into a long reverse engineering project.
Conclusion
Hopefully you have a basic understanding of web scraping. To close out, let’s review the keys to successful web scraping:
- Understand HTML elements and CSS selectors
- Inspect your returned data
- Write functions for reuse
- Include error handling to prevent data and time loss
- Conduct thorough research and tests before estimating the difficulty of a project